You have likely heard this quote and it neatly summarises the importance of – and competition for – data in today’s world. Yet just as oil must be refined before it reaches its peak value, raw data must be enhanced before it can power today’s AI technologies.
There is seemingly no limit on the amount of data we can create, either. Statista estimates that we will create more than 180 zettabytes of data worldwide between 2020 and 2025. A zettabyte is equivalent one sextillion bytes, or 10^21 (1,000,000,000,000,000,000,000) bytes. In other words, we are unlikely to run out.
Focus shifts, therefore, to the quality of the data at our disposal. Better data means better decisions; better decisions mean better results.
Yet IBM calculated that the annual cost of data quality issues in the U.S. amounts to $3.1 trillion. MIT Sloan Management Review “estimated that correcting data errors and dealing with the business problems caused by bad data costs companies 15% to 25% of their annual revenue on average.”
As a result, data quality management is an indispensable practice for retailers today.
What is data quality management?
Data quality management is a set of practices that aims to improve the state of information at a company’s disposal to complete business objectives.
To get to the heart of data quality management, we also need to understand the meaning of ‘data quality’.
Retailers can assess the quality of their data by benchmarking the following attributes:
Accuracy: The data corresponds to the reality it aims to reflect.
Completeness: All available data are recorded for customers in an accessible format.
Consistency: All relevant records are consistent for each individual customer across datasets.
Uniqueness: There are no duplicate records, with each customer’s ID recording only unique values.
Timeliness: Data is updated on a regular basis, in line with regulatory and business requirements.
Each attribute has an accompanying metric. For example, the accuracy of data can be tracked by monitoring the percentage of inaccurate records in a dataset.
Data quality management is a nascent field and many businesses still overlook its importance.
The above are just the basics to get up and running. Sophisticated retailers then move on to data augmentation, where they use zero- and first-party data to augment the quality of their information.
For instance, they can layer on style preferences and taste profiles to these database records. That lays the groundwork for advanced personalisation and multimodal search, but this process all begins with analysing the five attributes of good quality data.
While there are metrics to judge “good” and “bad” data, this assessment is also contextual. Incomplete records or inaccurate customer information is inevitably a problem for any business, but other issues may be more or less significant depending on the company’s objectives.
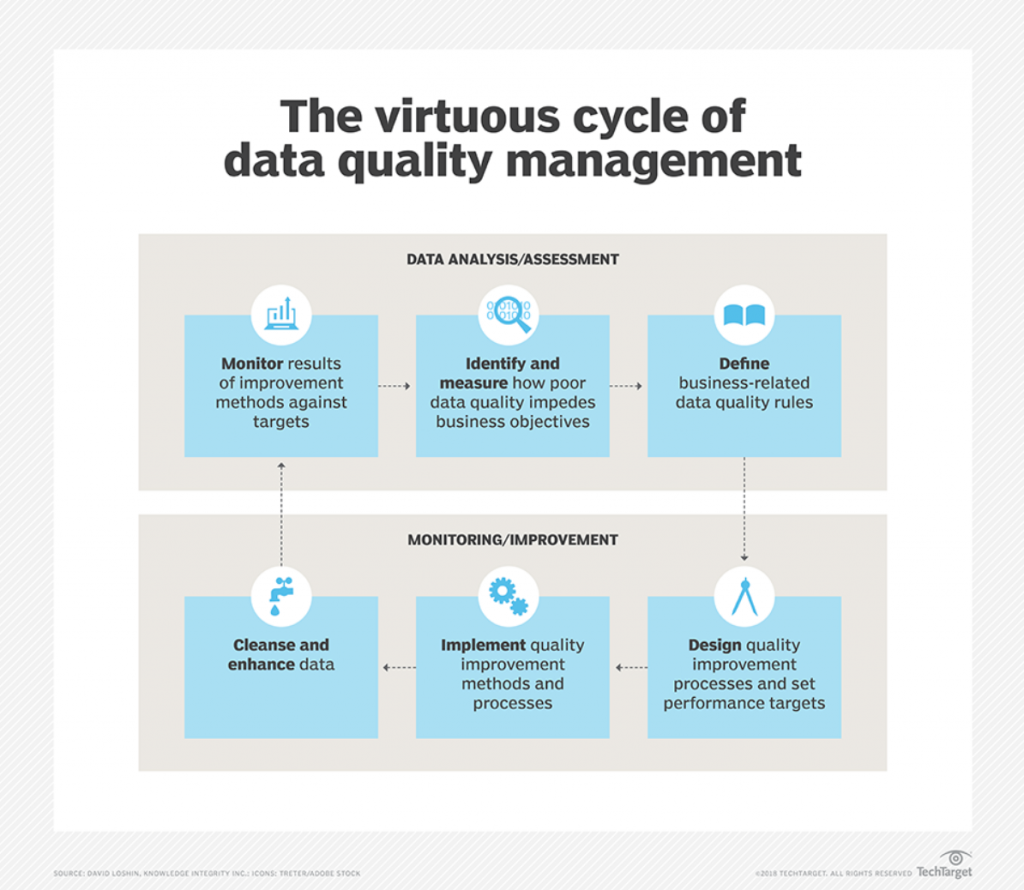
Therefore, the data quality management cycle kicks off with a measurement of data issues set against business goals. This helps to set performance targets and prepare a new process for improvement. The data is cleansed and enhanced, then measured again to see if its amelioration has indeed led to improved business performance.
Retailers can measure this improvement internally, for example in terms of staff time gained due to timely access to accurate data. Or they may choose to assess customer metrics, such as conversion rates or satisfaction scores.
Data quality management is overlooked, but that means it can also be a source of competitive advantage. Advanced retailers are making this a top priority today.
How Cadeera helps retailers improve their data quality
Cadeera’s AI technology for ecommerce works to its full potential when powered by high-quality data. We begin working with clients by assessing their data and layering on rich information through auto-tagging. This means that when customers visit the retailer’s website and search for products, Cadeera’s machine learning technology can match their intent to inspiration from the retailer’s inventory.
Get in touch today to learn more about Cadeera and arrange a demo.